California Ajax Solutions Team
www.CalAST.com
Appendix A: Database Basics
If you don't know anything about databases at all, this appendix should give you enough information to get you started. You don't need to be an expert to use DynaCRUX, but it really will help to understand the material presented here.
Tables
The most basic thing you need to know about databases is that they store data in tables. It might be easier to think of each table as a little spreadsheet, because they are arranged in much the same way. There are rows and columns, just like a spreadsheet, with each column representing a type of information (name, address, phone number) and each row representing an entry with the columns filled in with information about that entry. So, the most common "starter" example is usually something like this:
| Employee ID | Last Name | First Name | Phone | SSN | |
| 1 | Smith | John | 707-555-1212 | john.smith@mycompany.com | 123-45-6789 |
| 2 | Doe | Mary | 415-555-1212 | mary.doe@mycompany.com | 987-65-4321 |
The column headers are not stored in the table, but the database does remember the table structure and the names of the columns - it just keeps them somewhere else. Only the data itself is entered in the table.
That's about all you need to know to begin with, except that the columns have data types associated with them. Each column can contain information only if it agrees with the type of the column, which you set when you define the table. The most common types are integers (like Employee ID, above) and strings, but databases can contain floating point numbers, dates and times, and other types, plus variations on the basic types (like very small integers and very large ones). You need to think about all this when you design a database, but not generally when you use one.
A record is just another name for a row, and a field is just another name for a column. Everyone uses these terms interchangeably, which can be a bit confusing until you get used to it.
Keys
We'll just talk about the basics here, and return to this topic shortly.
Certain columns in a database are designated as keys, and are mostly used to establish the relationships between tables. In a way, you can't understand keys without understanding relationships, and vice-versa, so it's hard to decide which to start with. So just accept it that we need keys, and we'll tell you why in a moment.
Keys come in a few different types, but the most common are primary keys, which uniquely identify a row, and foreign keys, which are columns that contain references to rows in other tables. Databases do not require you to have these keys, but they are necessary to establish how tables are tied together so you can get meaningful information from your database.
Relationships
To find things in a database, you issue a query telling the database program what you want to know. These generally require that you know something about the relationships between tables. Of course, DynaCRUX is designed to minimize this requirement - except for administrators, of course.
Consider the sample database BookBlog, which allows members to write comments about the books they are reading. We'll skip the blog part for now, and just point out that there is a table of books and a table of authors. For simplicity, we'll just assume that book has only one author (which is not always true). However, one author can write many books, so we want to establish what is called a one-to-many relationship (or many-to-one, depending on where you start) between an author and her books.
So how do we tie the book table and the author table together? Each has a primary key that uniquely identifies the row in the table. For the book table, the primary key identifies the book; for the author table, it uniquely identifies the author. We use numbers for these keys, because there can be more than one book or more than one author with the same name.
To establish the relationship, we provide a foreign key column (author_id) in the books table that refers to the primary key (id) of the authors table. We could not really go the other way in this example, because a key can refer to only one thing. Since the author may have written many books, it can't "point to" all of them. Thus, the relationship is defined so that each of those books "points to" the same author.
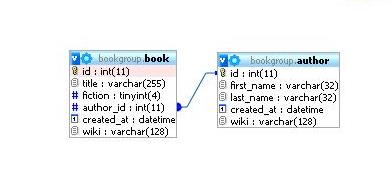
This picture also illustrates a number of things that we've talked about already, so let's make note of them.
- Note that there is a little picture of a key next to the first column (called id in both cases) of each table. This indicates that it is the primary key of the table.
- The connecting line indicates the relationship between the foreign key "author_id" in the book table and the primary key "id" in the author table.
- The name and type of each column is specified, as well as the size. You don't need to worry about this too much, but it's sometimes useful. So after the column name "title" in the book table, it specifies "varchar(255)" which just means that it is a variable length string up to 255 characters long.
- Both tables have a date/time field so we can record when each book or author was added.
Now let's look at a slightly harder idea - the many-to-many relationship. The BookBlog has a group of members, and each one is likely to read a review and decide to read the same book. So we have a member who reads many books, and a book that is read by many members. Thus, we need some way to record this information, along with whatever else we choose to record about this member having read this book.
We do this through what is called a join table. Here's what it looks like:
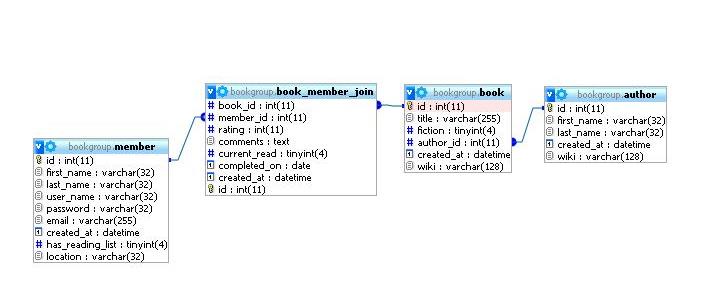
We've left the relationship between book and author in place, but added two new tables. The table book_member_join is the above-mentioned join table, which records not only who read which books, but also includes additional information about that relationship (like when this person finished reading this book). This is also where the reviews are stored.
We also show the member table, which describes each reader.
Let's take a minute to review why we needed the join table. Remember that each reference (foreign key) can refer to exactly one thing. So while you could easily express the idea that a reader could read many books, or that a book could be read by many readers, there's really no other way to say that both these things could be true. The join table solves this problem by recording "pairs" of information - one book and one reader per row. We also find it useful to record other information there, but many (probably most) join tables contain only a pair of foreign keys.
More about Keys
In the above diagram, the primary key for the join table (id) is the last item shown. In fact, this is probably a marginal design. Normally, a join table would have dual primary keys. That is, both book_id and member_id would be primary keys in the table. This needs a bit of explanation.
We already said that a primary key must be unique - but we know that the whole purpose of the join table is to allow many-to-many relationships. These are not unique, so how can this be? The answer is that a dual primary key does not mean that each part is unique, it means that the combination is unique. So each member can read (or at least review) each book only once, and there would be exactly one row for the combination of that member and that book. In such a case, we could get rid of the id field, which is really not needed.
You are not limited to only two primary keys. You could have three or more, but this is unusual.
At this point, you might be thinking that since we said that the member_id and book_id are foreign keys referring to their respective tables, how can they be primary keys? And the answer is - they would be both if we made this change. There's no rule that says a key can't be both primary and foreign. Here, each key individually is a foreign key, and in combination is a primary key.
Are all keys primary or foreign? Not necessarily. In our wine list example, we use a sort key that happens not to be the primary key of its table, but is a key that is referenced by another table's foreign key. So this tells us that the reference of a foreign key does not always have to be a primary key. It does have to be unique, though. It would not work if it was a reference to something that could appear more than once. So you can declare a column in a table to be a unique key (not necessarily primary) and use it as the "target" of a foreign key reference.