California Ajax Solutions Team
www.CalAST.com
Chapter 2: Building a Simple Report
You are the owner of the famous restaurant "Chez Moi" and of course you have an excellent wine cellar. Being so successful, you are always buying new wines and running out of old ones. So you eventually got someone (a talented waiter with too much time on his or her hands?) to create a database for you. Now, whenever someone buys a bottle of wine to go with dinner, you can remove it from inventory. And when you find a wine you like and buy a case of it, you can add it to the stock on hand.
Having the information in the database is useful, and you can use your computer systems to look things up. But diners are traditional, and they like to look at a printed wine list along with the menu so they can think about what food and wine they want to order. So you would like to run off copies of the wine list as menu inserts. After all, the available wines may change from day-to-day, and you want the wine list to be accurate. You also want to periodically run an inventory report to see what you might be running out of.
This sort of thing is easy with DynaCRUX, so let's see how this can be done. (We'll leave the inventory report to the next chapter, since it introduces some new features.)
Also, we want to introduce you to DynaCRUX gently, and like any powerful program is has a set of features that can be a bit overwhelming at first. So we will postpone discussion of anything beyond producing a very basic report until the next chapter as well.
The first step in understanding how to make a wine list is to look at the database.
The Data Model
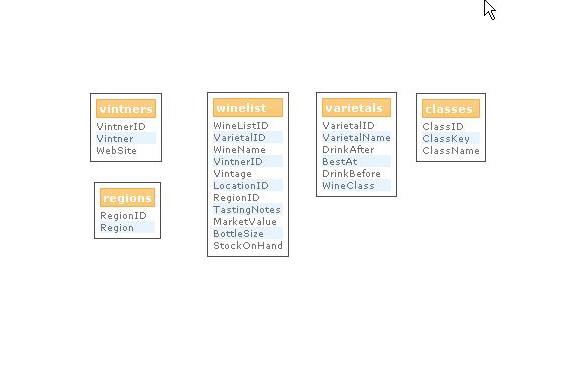
Like many databases, this one has one table that is the "heart" of the system. In DynaCRUX, this is called a base table. In our wine database, the table is called winelist, and has one record per wine. It does reference a number of other tables that provide additional information about classifying the contents of winelist. These are as follows:
- Varietal specifies what kind of wine it is - chardonnay, merlot, zinfandel, etc.
- Region specifies where the grapes were grown - France, Italy, California/Napa Valley, and so on
- Vintner tells you who made the wine.
Each of these is stored in its own table, with a primary key. The winelist table has foreign keys that reference these primary keys. If you don't understand what a primary key or a foreign key is, you might want to take a few minutes to review Appendix A.
The winelist table itself contains useful information, like how many bottles are in stock. Since we don't like to lose information, we never delete records. When a wine is out of stock, it just stops appearing on the printed wine list, but it stays in the database forever. That way, some customer can ask what wine he had with dinner three years ago and we might be able to help.
Just to make things interesting and to show how you can make a nicer (or more conventional) wine list for your customers, we will add a wine classes table. This will allow us to assign a class (e.g., red wines) to each varietal so that we can group wines by class. By convention, wine classes are not sorted by name, but usually with sparkling wines wines first, white wines next, red wines later, and dessert wines last. (You could have many more distinctions, and many restaurants do, but we want to keep things a bit under control here.) So will introduce a sort key in addition to the name of the wine class, which is well within the capability of DynaCRUX.
The real-world implementation of the wine tracking database has more tables, but the five we have introduced here (winelist, classes, vintners, regions, and varietals) are enough for an introductory example. The following diagram shows the five tables. In each case the first field listed is the primary key.
Now that we understand the data model, let's take a look at the desired report and what we need to support its generation.
The Wine List Report
What the customer sees is a subset of the information in the database. For example, you need to know where the wine is, the customer doesn't. While the customer needs to know how much the wine will cost, the customer doesn't need to know what you paid for it. So we only need to consider a few things that the customer will need to know to choose a wine, and we will add a few fields for grouping (more about that later). Given that this is what we need to print for this report, that gives us a good starting point for what we need to include in the database descriptor template file. Here's our list:
- wine class key - the one used for sorting
- wine class name - the one used for printing
- varietal
- vintage year
- vintner
- label - e.g., the name of the chateau or the name of the vineyard
- region
- price
So, although there are five tables, some of which can have many fields, you can see we are only interested in eight fields here (of which only seven will be displayed). Other reports may require different fields, but this is a good start. We will add some more when we do the inventory report.
The Template File Entries
Since the template file is written in XML, you're going to see a lot of it here. Don't be intimidated by the XML syntax. It's just a way of expressing data in a structured form. There are many good introductory tutorials on the web, and any one of them will teach you how to read it in five minutes or less. Or just plunge ahead and figure it out by reading.
We're going to show you how to create a minimal template file manually, which can be done in any text editor. The idea here is to reinforce the idea that you don't need to include everything, just what you are going to use. But we want to mention that you can use DynaCRUX to generate a complete picture of your database tables (or just some of them) automatically. We'll talk about template generation in a future chapter.
The first thing we have to do is create template objects for the eight fields me mentioned above. Remember, DynaCRUX can deal with objects that are not fields, but here everything is directly stored in a database table. DynaCRUX calls such simple objects elements.
What do we need to specify about an object? Clearly, we have to give it a name, and tell the software where to find it. Due to the various naming conventions used, we actually assign three names to each object (sorry, it's useful to do it this way):
- The xml name is in a form legal for data transmission, conventionally all lower case with no spaces
- The display name is "prettier" - it can contain spaces and capitalization
- The query name is the one used by the database, and can be different from either of the above.
So, here is the XML for the label object, the most complicated in that its names are quite different:
<object>
<displayname>Label</displayname>
<queryname>WineName</queryname>
<xmlname>winename</xmlname>
<type>element</type>
<table>winelist</table>
</object>
In the report, this object prints as "Label" but in the database table (see the above diagram), it is called "WineName"; in the XML form, it's just "winename." These could have all been the same, but there is more flexibility provided by allowing for different names. We note that this is an element, and that it is found in the winelist table.
Note that all this complexity is in the template file. In the report file, it just looks like this (the XML name is used):
<item><xname>winename</xname>
<column>3</column>
<format>text</format>
</item>
The other object descriptors are quite similar, so we won't repeat them here. In theory, you could extract all the information you needed from the database with just the objects, since you know which table stores the data and what the column name is called. In the real world, database queries need to factor in the relationship between tables as well. If you are familiar with SQL and what queries return (called the result set), you already know this. If you are not that familiar with databases, just accept it that if you don't write queries with structure in mind, you get back a lot more data than you really wanted. Then you have to process what you got back to obtain something manageable. It's better to let the database do the work!
DynaCRUX generates queries that solve this problem, but of course it knows nothing about your database structure until you tell it. The template file includes a language for doing so, which we will now consider.
Most properly designed (normalized) database tables contain a primary key. This is a unique value that can be used to identify exactly one record in the table, and is usually a small integer. We noted above that the main table, winelist, contains foreign keys. These are usually also small integers that are references to the primary key of some other table. The fields don't need to be integers at all, but they often are. What is important is that the value of the foreign key in one table exactly matches the value of the primary key in the referenced table.
So the first job is to tell DynaCRUX the name of a table, and which column is the primary key. This is simply:
<table>
<name>vintners</name>
<key>VintnerID</key>
</table>
Note that you don't need anything more than this; it is not necessary to describe the whole table. What about specifying the foreign key? If a table contains foreign keys, we list them along with the primary key as references.
<table>
<name>winelist</name>
<key>WineListID</key>
<references foreignkey="VarietalID">varietals</references>
<references foreignkey="VintnerID">vintners</references>
<references foreignkey="RegionID">regions</references>
</table>
Here we specify that the winelist table references three other tables (varietals, vintners, and regions) and we give the name of the foreign key (the one in the winelist table) that is the reference. Note that we don't mention the name of the primary key of the "other" table here. That's because we already provided that information in the table descriptor for the referenced table. If you don't tell it otherwise, DynaCRUX assumes the reference is always to the primary key of the other table. There's a way to specify that some other key is referenced, as we will see later.
Now DynaCRUX can generate proper JOINs in the query to return exactly one row per wine, which is what we want. (Don't worry if you don't know what a JOIN is. It's all part of making the database do the work so you don't have to.)
In fact, there is one further piece of information that DynaCRUX needs to work best. That is, we need to specify that the winelist table is the base table. What this means to DynaCRUX is that queries are "directed to" the winelist table first, then other tables as needed to obtain more information. In SQL terms, this forces DynaCRUX to generate queries with a FROM clause of the form:
FROM winelist LEFT JOIN vintners ON ...
Controls and Filters
There's one more specification we would like to add for this report - we only want to list wines we actually have available. Remember that we never throw data away for historical reasons, but we don't want to offer wines to customers if we don't have any to serve. So we add a filter to the report that specifies we only want in stock wines.
In DynaCRUX, terms control and filter are closely related. They are really just two parts to the same solution to selecting only some data for a report. The filter can be thought of as the "back end" of the process - it is used to generate a query that selects only the data you are interested in. In contrast, the control is a user interface element that is used to tell DynaCRUX that you want to filter.
Filters come in two "flavors" - a design-time filter is built into a report and is always applied in the same way. Our "wines in stock" filter is like this; we just need to know that this report only includes wines that have an inventory level greater than zero. In contrast, we can also create a run-time filter that collects information each time the report is run. For example, a billing system might want to report on all invoices sent during the previous month, but the month would be different every time you ran the report. You don't want to change the report itself every month, so you supply a run-time filter to collect this information for you with an associated control.
In this example, the filter is very simple and can be specified as a design-time filter in the template file. Any report that wants to use the filter just asks that it be used as part of the report definition. How does this happen? When you design the report, the control appears as part of the report designer. If you are manually creating a report with a text editor (too much work in our opinion), you would just have to know it was there.
For security reasons, we do not allow passing SQL across the client-server interface. This is extremely dangerous, and can lead to what are called SQL injection attacks. Thus, you are only allowed to store the name of a filter in a report, not its contents. However, the template file must know what that name means, so we allow you to define it as follows:
<control scope="design">
<type>checkbox</type>
<label>Only wines in stock</label>
<name>instock</name>
<filter>winelist.StockOnHand>0</filter>
</control>
Since the greater than sign (>) is not legal in XML, we have to substitute the special sequence ">" for it. The Template Builder application does this for you.
When you use the Report Designer, it will ask you if you want this filter applied to the report you are designing. It does this by displaying the label and a checkbox (because that's its type). If you check the box, then the report file will contain the only things it needs to know about this filter - its name and value:
<usesfilter value="1">instock</usesfilter>
The value here is simple (1, or on) because it's a check box. The filter is either included or not included. Some filters have values, too, but these are only slightly different. if you had a filter that asked for the operator's name and passed that in to the report, it would look something like:
<usesfilter value="Bob">operatorname</usesfilter>
Adding a Sort Key
Are we done yet? We would be, except that we wanted to show an additional capability having to do with non-standard sorting using a sort key. Yes, this adds complexity, but this is the perfect example to show how this works. Remember that we wanted our wines grouped in conventional wine list order - sparkling wines, followed by white wines, followed by red wines, followed by desert wines. Clearly, alphabetical sorting is not going to work here. So we introduce a simple sort key:
- a: sparkling wines
- b: white wines
- c: red wines
- d: dessert wines
We don't need to add this to every wine on the list, because a given varietal is always in the same wine class. Champagne is always "a", cabernet sauvignon is always "c", and so on. So we make this a reference from the varietals table to the wine classes table. The varietals table is already referenced from the wine list table, so everything is connected. The complication is that the sort key is not the primary key of the classes table (although it could have been), so we need to express things slightly differently.
<table>
<name>varietals</name>
<key>VarietalID</key>
<references foreignkey="WineClass" column="ClassKey">classes</references>
</table>
Here, the reference notes that the column WineClass in the varietals table refers to column ClassKey in the classes table, instead of the primary key of that table.
Now the template should contain everything about retrieval that we need to produce this first report. We have not shown you every definition or every object, but remember that this is a simple example.
The Report File for the Wine List
So far, we have not said very much about the report itself - just what the template must know to produce the report. In part, this is because the report itself is fairly trivial compared to he template. Remember, the template has to know everything that is possible. The report just has to know what you want. Here is the complete specification for the basic wine list report:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE report SYSTEM "report.dtd">
<report version="2"><template>winelistGen.xml</template>
<!-- Datasets section -->
<dataset id="dcxPDS"><dstype colopt="browser">table</dstype>
<usesfilter value="1">instock</usesfilter>
<item><xname>classkey</xname>
<sort direction="asc">1</sort>
<format>text</format>
</item>
<item><xname>classname</xname>
<group>1</group>
<format>text</format>
</item>
<item><xname>region</xname>
<column>4</column>
<format>text</format>
</item>
<item><xname>varietalname</xname>
<sort direction="asc">2</sort>
<group>2</group>
<format>text</format>
</item>
<item><xname>vintner</xname>
<sort direction="asc">4</sort>
<column>2</column>
<format>text</format>
</item>
<item><xname>winename</xname>
<column>3</column>
<format>text</format>
</item>
<item><xname>vintage</xname>
<sort direction="asc">3</sort>
<column>1</column>
<format>text</format>
</item>
<item><xname>marketvalue</xname>
<column>5</column>
<format>usd</format>
<label>Price</label>
</item>
</dataset>
</report>
At the top, we see information that applies to the entire report - here, just the name of the template on which it is based. A report can contain any number of datasets, but here we have only one - so there is only one dataset section. We describe its type (e.g., write results to a table) and note that there is a filter - one described in the template - that applies here.
We then provide a list of the items associated with this dataset. Some of these are just display columns, which only have a name, a format (e.g., text), and a column number. Others have sorting or grouping details. The app that runs reports knows how to process all these items to generate SQL, run the query, and then build the results table.
We note that there are four sort items, used to build the ORDER BY clause in the generated SQL. The first is classkey, which is important for ordering but isn't even displayed. Instead, its associated classname is what shows up on the screen. The second is varietalname. These two are used for grouping, which is why it is important that they come first in the sort order. The other two sort items affect the order of rows in the table.
The two group items (classname and varietalname) are used to build a GROUP BY clause in the generated SQL. These will become section headers in the table.
The remaining five items are presented as columns in a table. Let's take a closer look at the list of columns. These will represent the five columns of data that will appear in the display table, in order. We supply only the XML name of the object that goes in the column, its format, and its column order, with the exception of the last item. This is the marketvalue object, but we want to call it Price in the table. We can easily do this by adding a label node with the value "Price" to the specification. Now the wine list will call this column something other than its default display name. The display names of these five columns become headers in the table, unless there is an override as in the last item:
| Vintage | Vintner | Label | Region | Price |
The above very simple report file would produce something like the following:
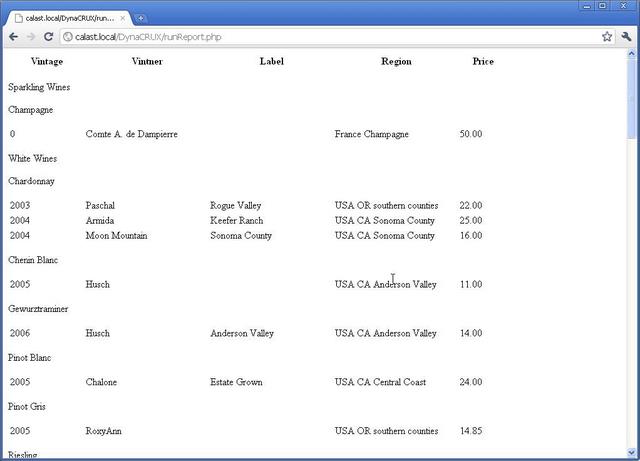
From this web page, you could simply print the page (adjusting your browser to turn header and footer information on or off) and you would be done.
Of course, it's not visually interesting. You can use styling rules to improve the report's appearance by adding more details to the presentation section of the report. This allows you to have fine control over what your report looks like. We will discuss this more in Chapter 3: Adding Style and Other Reports.